
이진 탐색(Binary Search) : 반으로 쪼개면서 탐색하기
예시의 그림은 “이것이 취업을 위한 코딩 테스트다 with 파이썬” 교재를 참고한 것임.
배열 내부의 데이터가 정렬되어 있어야만 사용할 수 있는 알고리즘이다.
이진 탐색은 위치를 나타내는 3개의 변수를 사용하는데, 탐색하고자 하는 범위의 시작점, 끝점, 그리고 중간점이다. 찾으려는 데이터와 중간점 위치에 있는 데이터를 반복적으로 비교해서 데이터를 찾는다.
예시
10개의 데이터 중에서 값이 4인 원소를 찾는 예시이다. 초기값이 정렬되어 있는 것이 중요하다.
step 1
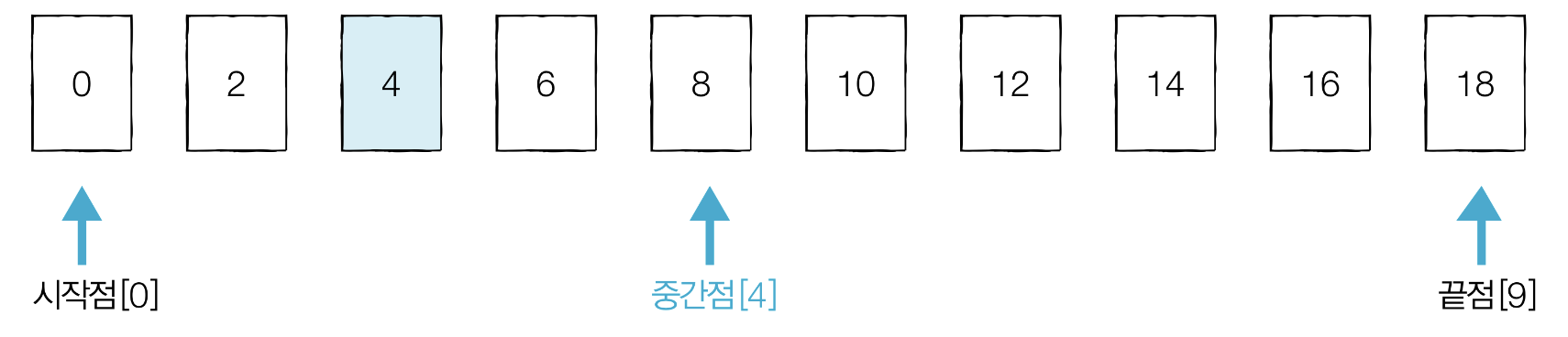
시작점과 끝점을 확인하고 중간점을 정한다. 중간점이 실수일 때는 소수점 이하를 버린다. 예시에서는 중간점이 4.5에서 소수점 이하를 버려서 [4]이다. 중간점 [4]의 데이터 8이 더 크므로 중간점 이후의 값은 확인할 필요가 없다. 그다음 끝점을 [4]의 이전인 [3]으로 변경한다.
step 2
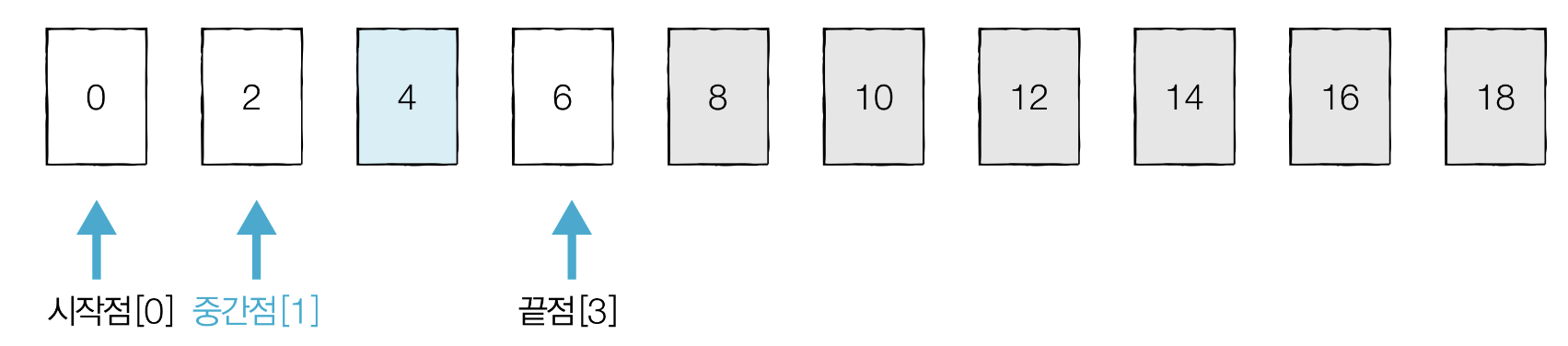
중간점에 위치한 데이터 2는 찾으려는 데이터 4보다 작으므로 2이하인 데이터는 확인할 필요가 없다. 그다음 시작점을 [2]로 변경한다.
step 3
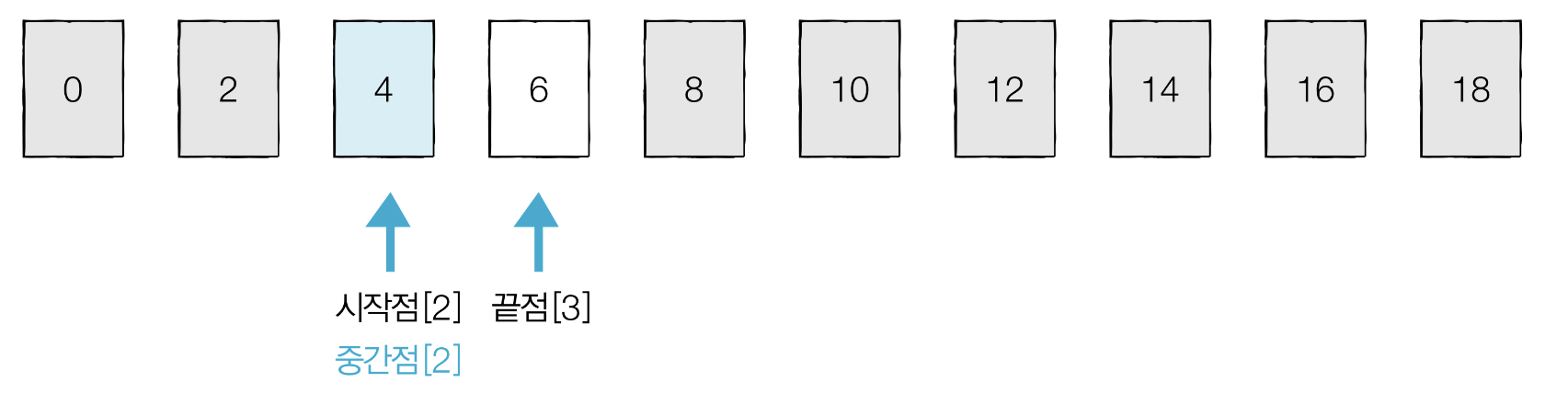
중간점은 2.5에서 소수점을 버려서 [2]이다. 중간점에 위치한 데이터 4는 찾으려는 데이터와 동일하므로 탐색을 종료한다.
전체 데이터는 10개지만, 이진 탐색을 이용해 총 3번의 탐색으로 원소를 찾을 수 있었다. 이진 탐색은 한 번 확인할 때마다 확인하는 원소의 개수가 절반씩 줄어든다는 점에서 단계마다 2로 나누는 것과 동일하므로 연산 횟수는 $log_2N$에 비례하여 시간 복잡도가 $O(logN)$이다.
소스코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 이진 탐색 소스코드 구현(재귀 함수)
def binary_search(array , target , start , end):
if start > end : # 값을 못 찾는 경우 mid + 1 이므로
return None
mid = ( start + end ) // 2 # 몫만 구하기 위해
# 찾은 경우 중간점 인덱스 반환
if array [ mid ] == target :
return mid
# 중간점의 값보다 찾고자 하는 값이 작은 경우 왼쪽 확인
elif array [ mid ] > target :
return binary_search ( array , target , start , mid - 1 )
# 중간점의 값보다 찾고자 하는 값이 큰 경우 오른쪽 확인
else :
return binary_search ( array , target , mid + 1 , end )
# n (원소의 개수)과 target (찾고자 하는 문자열)을 입력받기
n, target = map(int, input().split()) # 전체 원소 입력받기
array = list(map(int, input().split()))
# 이진 탐색 수행 결과 출력
result = binary_search ( array , target , 0 , n - 1 )
if result == None :
print ("원소가 존재하지 않습니다.")
else :
print ( result + 1 )
코딩 테스트에서 이진 탐색은 단골로 나오는 문제이니 가급적 외우길 권장한다.
코딩 테스트의 이진 탐색 문제는 탐색 범위가 큰 상황에서의 탐색을 가정하는 문제가 많다. 따라서 탐색 범위가 2,000만을 넘어가면 이진 탐색으로 문제에 접근해보자.
처리해야 할 데이터의 개수나 값이 1,000만 단위 이상으로 이진 탐색과 같이 $O(logN)$의 속도를 내야 하는 알고리즘을 떠올려야 문제를 풀 수 있는 경우가 많다.
트리 자료구조
이진 탐색은 전제 조건이 데이터 정렬이다. 데이터베이스는 내부적으로 대용량 데이터 처리에 적합한 트리 자료구조를 이용하여 항상 데이터가 정렬되어 있다.
따라서 데이터베이스에서의 탐색은 이진탐색과는 조금 다르지만 이진 탐색과 유사한 방법을 이용해 탐색을 항상 빠르게 수행하도록 설계되어 있어서 데이터가 많아도 탐색하는 속도가 바르다.
큰 데이터를 처리하는 소프트웨어는 대부분 데이터를 트리 자료구조로 저장해서 이진 탐색과 같은 탐색 기법을 이용해 빠르게 탐색이 가능하다.
이진 탐색 트리
이진 탐색이 동작할 수 있도록 고안된, 효율적인 탐색이 가능한 자료구조로 다음과 같은 특징을 가진다.
- 부모 노드보다 왼쪽 자식 노드가 작다.
- 부모 노드보다 오른쪽 자식 노드가 크다.
이진 탐색 트리 자료구조를 구현하도록 요구하는 문제는 출제 빈도가 낮으므로, 이진 탐색 트리가 미리 구현되어 있다고 가정하고 데이터를 조회하는 과정만 알아보자.
예시
예시의 그림은 “이것이 취업을 위한 코딩 테스트다 with 파이썬” 교재를 참고한 것임
찾는 원소가 37일 때,
step 1
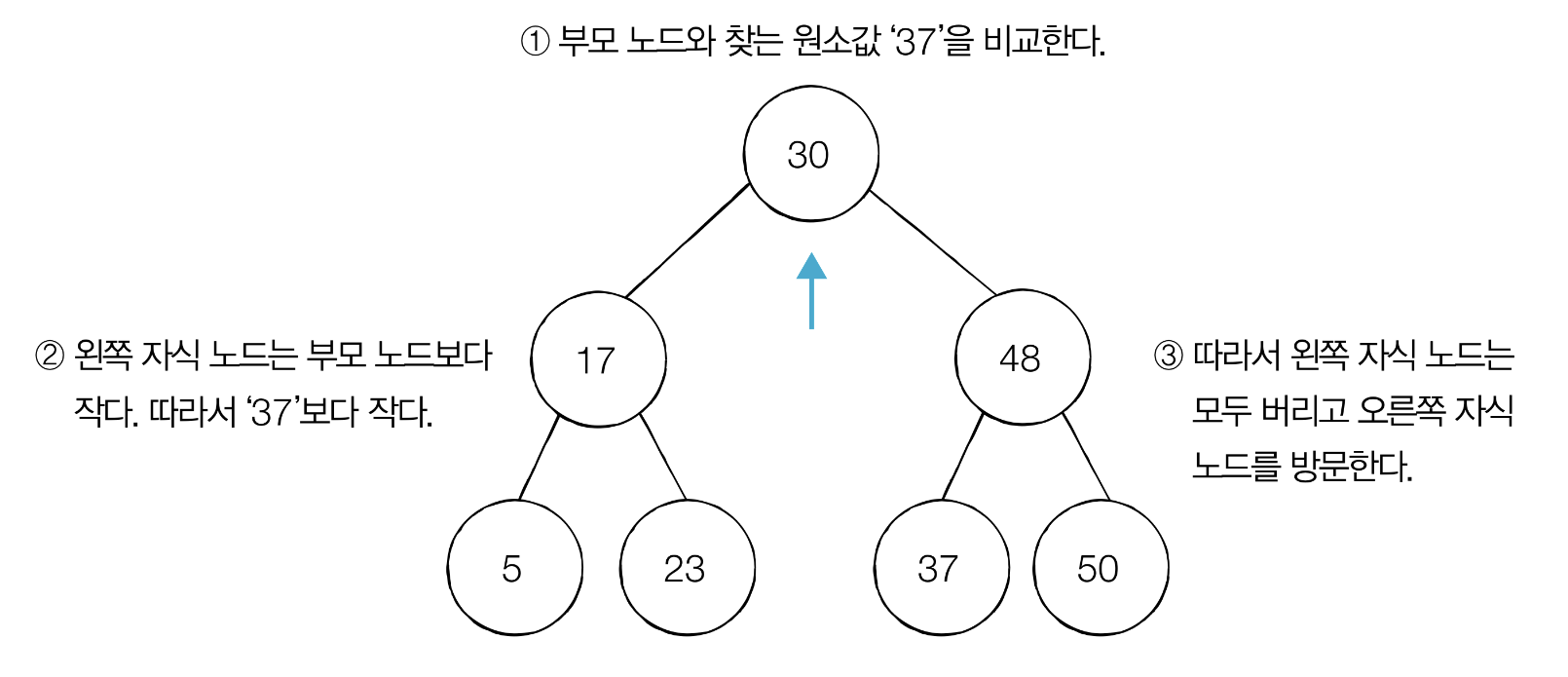
루트노드에서 부모 노드의 왼쪽 자식 노드는 30이하이므로 왼쪽에 있는 모든 노드는 확인할 필요가 없다.
step 2
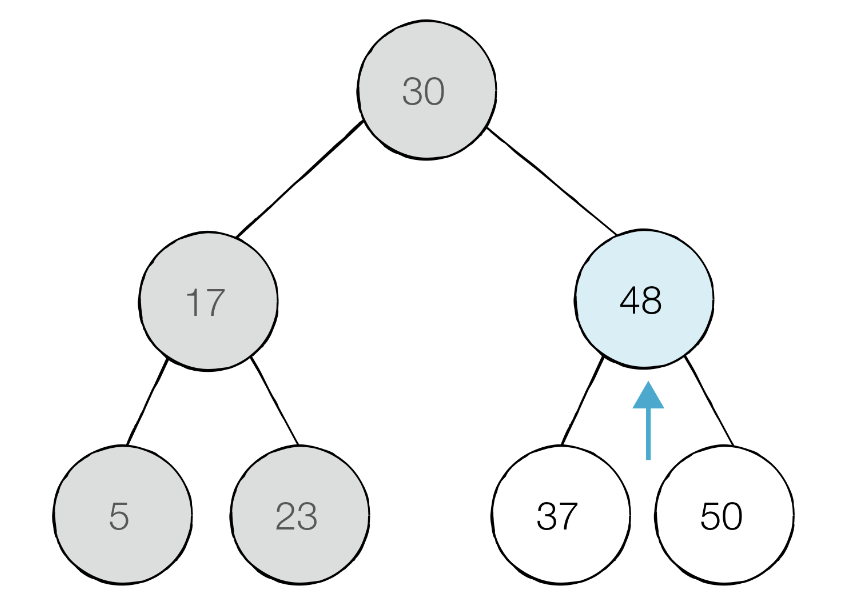
48 부모 노드에서 오른쪽 자식 노드는 모두 48이상이므로 확인할 필요가 없다.
step 3
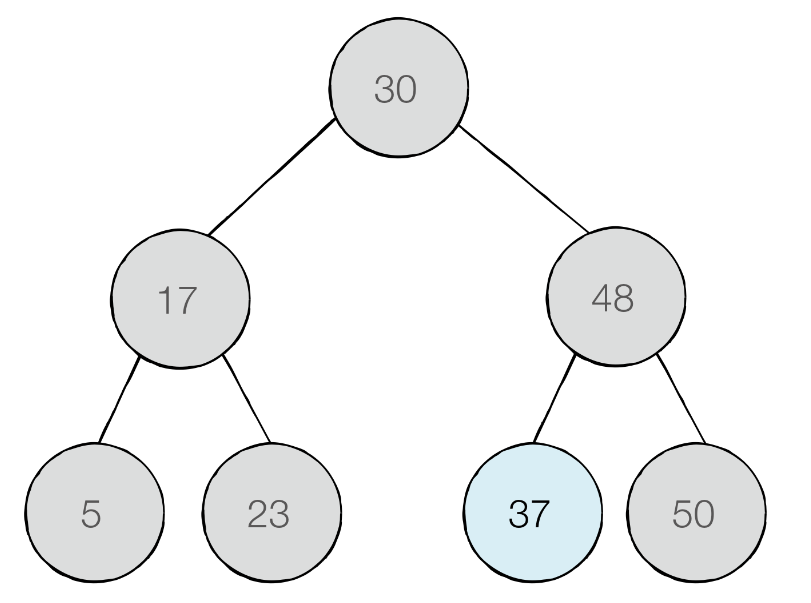
현재 방문한 노드의 값이 찾는 값과 일치하므로 탐색을 마친다.
빠르게 입력 받기
이진 탐색 문제는 입력 데이터가 많거나 탐색 범위가 매우 넓은 편이다. 데이터의 개수가 1,000만개를 넘어가거나 탐색 범위의 크기가 1,000억 이상이라면 이진 탐색 알고리즘을 의심해보자.
입력 데이터가 많은 문제는 sys 라이브러리의 readline() 함수를 이용하면 시간 초과를 피할 수 있다. sys 라이브러리를 사용할 때는 한 줄 입력 받고 나서 rstrip() 함수를 꼭 호출하자. readline()으로 입력하면 입력 후 엔터가 줄바꿈 기호로 입력되는데 이 공백 문자를 제거할 수 있다.