
1. [ ]
- 문자 클래스로 만들어지는 정규식은, [ ]로 둘러쌓인 내부의 문자열과 매치되는 것이라는 의미
1
2
3
4
5
6
7
8
9
10
11
12
13
import re
# r은 Raw String (원시 문자열)을 나타내는 접두사
# 파이썬에서 Raw String은 백슬래시 \를 이스케이프 시키지 않고 그대로 사용할 수 있도록 해줌
pattern = r'[aiueo]'
strings = ['apple', 'banana', 'aaii', 'bbb', 'ccc']
for string in strings:
if re.search(pattern, string):
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘apple’ matches the pattern. [‘a’, ‘e’] ‘banana’ matches the pattern. [‘a’, ‘a’, ‘a’] ‘aaii’ matches the pattern. ‘banana’ matches the pattern. [‘a’, ‘a’, ‘a’] ‘aaii’ matches the pattern. [‘a’, ‘a’, ‘i’, ‘i’] ‘bbb’ does not match the pattern. ‘ccc’ does not match the pattern.
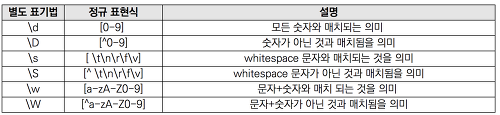
자주 사용되는 문자클래스는 아래와 같이 별도의 표기법으로 사용될 수있음
![Untitled]()
1
2
3
4
5
6
7
8
9
10
import re
pattern = r'[\d]'
strings = ['a', '2a', '3', 'aaa']
for string in strings:
if re.search(pattern, string):
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘a’ does not match the pattern. ‘2a’ matches the pattern. [‘2’] ‘3’ matches the pattern. [‘3’] ‘aaa’ does not match the pattern.
- 문자클래스 내부에서 쓰이는 ^ 는 뒤에서 알아볼 메타문자와는 다른의미인, not의 의미를 가지고 있음
1
2
3
4
5
6
7
8
9
10
import re
pattern = r'[^aiueo]'
strings = ['apple', 'banana', 'aaii', 'bbb', 'ccc']
for string in strings:
if re.search(pattern, string): # a,i,u,e,o가 아닌 모든 문자를 찾음. 있으면 참
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘apple’ matches the pattern. [‘p’, ‘p’, ‘l’] ‘banana’ matches the pattern. [‘b’, ‘n’, ‘n’] ‘aaii’ does not match the pattern. ‘bbb’ matches the pattern. [‘b’, ‘b’, ‘b’] ‘ccc’ matches the pattern. [‘c’, ‘c’, ‘c’]
2. . (Dot)
- .(Dot) 은 줄바꿈 문자인 \n을 제외한 모든 하나의 문자와 매치되는 것을 의미
1
2
3
4
5
6
7
8
9
10
import re
pattern = r'a.b'
strings = ['aasdfb', 'asb', 'a2b', 'sdfba', 'ab']
for string in strings:
if re.search(pattern, string):
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘aasdfb’ does not match the pattern. ‘asb’ matches the pattern. [‘asb’] ‘a2b’ matches the pattern. [‘a2b’] ‘sdfba’ does not match the pattern. ‘ab’ does not match the pattern.
1
2
3
4
5
6
7
8
9
10
import re
pattern = r'a...b'
strings = ['aasdfb', 'asb', 'a2b', 'sdfba', 'ab']
for string in strings:
if re.search(pattern, string):
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘aasdfb’ matches the pattern. [‘asdfb’] ‘asb’ does not match the pattern. ‘a2b’ does not match the pattern. ‘sdfba’ does not match the pattern. ‘ab’ does not match the pattern.
3. *****
- *는 반복을 나타내는 메타문자로써, 해당 메타문자 앞의 글자가 0번이상 반복되는 모든 문자열과 매치
1
2
3
4
5
6
7
8
9
10
import re
pattern = r'go*gle'
strings = ['ggle', 'gogle', 'google', 'gooooogle', 'goooooog']
for string in strings:
if re.search(pattern, string):
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘ggle’ matches the pattern. [‘ggle’] ‘gogle’ matches the pattern. [‘gogle’] ‘google’ matches the pattern. [‘google’] ‘gooooogle’ matches the pattern. [‘gooooogle’] ‘goooooog’ does not match the pattern.
4. +
- +는 *과 같은 반복을 나타내는 메타문자. *는 다르게 앞의 글자가 0번을 제외한, 1번이상 반복되는 모든 문자열과 매치
1
2
3
4
5
6
7
8
9
10
import re
pattern = r'go+gle'
strings = ['ggle', 'gogle', 'google', 'gooooogle', 'goooooog']
for string in strings:
if re.search(pattern, string):
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘ggle’ does not match the pattern. ‘gogle’ matches the pattern. [‘gogle’] ‘google’ matches the pattern. [‘google’] ‘gooooogle’ matches the pattern. [‘gooooogle’] ‘goooooog’ does not match the pattern.
5. {m,n}
- {m,n}또한 반복을 나타내는 메타문자. 위와는 다르게 반복횟수를 m과 n으로 정할 수 있음. 즉, 앞의 문자가 m번 이상 n번이하 반복되는 모든 문자열과 매치
1
2
3
4
5
6
7
8
9
10
import re
pattern = r'go{1,3}gle'
strings = ['ggle', 'gogle', 'google', 'gooooogle', 'goooooog']
for string in strings:
if re.search(pattern, string):
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘ggle’ does not match the pattern. ‘gogle’ matches the pattern. [‘gogle’] ‘google’ matches the pattern. [‘google’] ‘gooooogle’ does not match the pattern. ‘goooooog’ does not match the pattern.
6. ?
- ? 는 앞의 문자가 0~1번 반복되는 모든 문자열과 매치
1
2
3
4
5
6
7
8
9
10
import re
pattern = r'go?gle'
strings = ['ggle', 'gogle', 'google', 'gooooogle', 'goooooog']
for string in strings:
if re.search(pattern, string):
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘ggle’ matches the pattern. [‘ggle’] ‘gogle’ matches the pattern. [‘gogle’] ‘google’ does not match the pattern. ‘gooooogle’ does not match the pattern. ‘goooooog’ does not match the pattern.
7. |
해당 메타문자는 a b 와 같은 형식으로 사용되며 a 또는 b와 매치되는 문자열을 반환
1
2
3
4
5
6
7
8
9
10
import re
pattern = r'b|s'
strings = ['aasdfb', 'asb', 'a2b', 'sdfba', 'ab']
for string in strings:
if re.search(pattern, string):
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘aasdfb’ matches the pattern. [’s’, ‘b’] ‘asb’ matches the pattern. [’s’, ‘b’] ‘a2b’ matches the pattern. [‘b’] ‘sdfba’ matches the pattern. [’s’, ‘b’] ‘ab’ matches the pattern. [‘b’]
8. ^
- ^는 문자열의 맨처음을 의미하는 메타문자. 문자클래서 내부에서 not의 의미로 사용되기도 하므로 혼동되지 않도록 주의. 정규식으로 찾고자 하는 문자열의 앞에 입력
1
2
3
4
5
6
7
8
9
10
import re
pattern = r'^apple'
strings = ['apple', 'banana', 'apple mango']
for string in strings:
if re.search(pattern, string):
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘apple’ matches the pattern. [‘apple’] ‘banana’ does not match the pattern. ‘apple mango’ matches the pattern. [‘apple’]
1
2
3
4
5
6
7
8
9
10
import re
pattern = r'[^apple]' #
strings = ['apple', 'banana', 'apple mango']
for string in strings:
if re.search(pattern, string): # a,p,l,e가 아닌 모든 문자를 찾음. 있으면 참
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘apple’ does not match the pattern. ‘banana’ matches the pattern. [‘b’, ‘n’, ‘n’] ‘apple mango’ matches the pattern. [’ ‘, ‘m’, ‘n’, ‘g’, ‘o’]
9. $
- $는 ^와 반대로 문자열의 맨 마지막을 의미하는 메타문자. ^와는 다르게 매치할 문자열의 뒤에 입력
1
2
3
4
5
6
7
8
9
10
import re
pattern = r'apple$'
strings = ['apple', 'banana', 'apple mango']
for string in strings:
if re.search(pattern, string):
result = re.findall(pattern, string)
print(f"'{string}' matches the pattern. \n {result}")
else:
print(f"'{string}' does not match the pattern.")
‘apple’ matches the pattern. [‘apple’] ‘banana’ does not match the pattern. ‘apple mango’ does not match the pattern.
10. \A, \Z
- \A는 기본적으로 ^와 같이 문자열의 맨 처음을 의미하는 메타문자
- 하지만 다른점이 있다면 우리가 re.MULTILINE이라는 컴파일 옵션을 사용했을 때, ^는 라인별 문자열의 맨처음을 의미하지만 \A는 라인별이 아닌 문자열 전체에서의 맨 처음을 의미
1
2
3
4
5
6
7
8
9
10
import re
p = re.compile("^python\s\w+")
data = """python one
life is too short
python two
you need python
python three"""
print(p.findall(data))
[‘python one’]
^ 메타 문자를 문자열 전체의 처음이 아니라 각 라인의 처음으로 인식시키고 싶은 경우,
1
2
3
4
5
6
7
8
9
10
import re
p = re.compile("^python\s\w+", re.MULTILINE)
data = """python one
life is too short
python two
you need python
python three"""
print(p.findall(data))
[‘python one’, ‘python two’, ‘python three’]
- \Z는 기본적으로 $와 같이 문자열의 맨 뒤를 의미하는 메타문자
- 하지만 다른점은 \A와 같이, re.MULTILINE이라는 컴파일 옵션을 사용했을 때, $는 라인별 문자열의 맨뒤를 의미하지만 \Z는 라인별이 아닌 문자열 전체에서의 맨 뒤를 의미