
본 글은 ‘Hyper-v 환경에서 k8s 클러스터 구축’ 포스팅 이후 진행함
Background
- SaaS 제품을 사용하는 테넌트가 추가됨에 따른 환경 배포 및 관리가 불편해져 기존의 베어메탈 환경에서 쿠버네티스로 전환
- 기존 Bare-metal 환경에 직접 설치된 모니터링 스택들을 쿠버네티스 클러스터 위에 구축
- K8S 클러스터의 테넌트별 시스템 리소스 및 애플리케이션 사용량 모니터링을 가능하게 함 → 플랫폼의 가용성과 신뢰성을 보장
Prerequisite
- Helm v3.14.4+
- kubectl v1.28.2+
- StorageClass에서 사용될 CSI 드라이버 Provisioner
Helm Chart
- Chart Name:
- Chart Version: v58.2.1
- App Version(Prometheus-Operator): v0.73.2
kube-prometheus-stack Helm Chart에 사용되는 프로젝트
- Prometheus Operator
- prometheus-operator/prometheus-operator
- 쿠버네티스 네이티브하게 프로메테우스를 배포하고 관리할 수 있는 기능을 제공합니다.
- kube-prometheus
- prometheus-operator/kube-prometheus
- Prometheus Operator를 포함하여, Grafana, Prometheus Rule 등 모니터링 스택에 필요한 여러 컴포넌트가 종합되어 있습니다.
- helm charts
- prometheus-community/kube-prometheus-stack
- Prometheus Community에 의해 관리되며, kube-prometheus 프로젝트를 기반으로 하여 거의 유사한 기능을 Helm Chart로 관리하고 배포할 수 있도록 하는 프로젝트로 볼 수 있습니다.
즉, kube-prometheus 프로젝트를 구성하는 컴포넌트 중 하나가 Prometheus Operator 이며, Prometheus Community에서는 kube-prometheus를 기반으로 Helm Chart를 만들어서 Artifact Hub에 등록한 것으로 볼 수 있습니다.
kube-prometheus-stack 배포시 설치 되는 컴포넌트는 다음과 같습니다.
- The Prometheus Operator
- Highly available Prometheus
- Highly available Alertmanager
- Prometheus node-exporter
- Prometheus Adapter for Kubernetes Metrics APIs
- kube-state-metrics
- Grafana
Install Helm
1
2
3
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
PV, PVC의 동적 프로비저닝을 위한 NFS CSI 드라이버 구성
PV, PVC의 동적 프로비저닝을 위한 NFS CSI 드라이버 구성 포스팅 참고
Get prometheus-community Helm Repository
https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack
1
2
3
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
Helm Pull
1
helm pull prometheus-community/kube-prometheus-stack
- helm install 명령으로 바로 설치할 수도 있지만 values.yaml 파일을 직접 수정해서 배포하기 위해 pull을 사용
- main 버전 외에 다른 버전을 사용하려면 –version 옵션을 사용
1
tar xvfz kube-prometheus-stack-58.3.3.tgz
kube-prometheus-stack Helm 차트 구성
- kube-prometheus-stack을 포함한 대부분의 Helm 배포 패키지는 비슷한 구성으로 이루어져 있습니다.
- charts: Helm 차트의 종속 차트를 포함하는 위치입니다. 이 패키지의 경우 grafana, kube-state-metrics, prometheus-node-exporter가 존재합니다.
- templates: Helm 차트의 템플릿 파일들을 포함합니다. 템플릿은 Kubernetes 리소스의 정의를 작성하는 데 사용되며, 이를 통해 애플리케이션의 배포, 서비스, 구성 등을 관리할 수 있습니다
- crds: Custom Resource Definitions(CRDs) 파일을 포함할 수 있는 위치입니다. CRD는 Kubernetes API에 사용자 정의 리소스와 그에 대한 스키마를 추가하는 데 사용됩니다.
- Chart.yaml: Helm 차트의 메타 정보를 정의합니다. 메타 정보에는 차트의 이름, 버전, 유형, 유지 보수자 정보 등이 포함됩니다. 또한 종속 차트, 애플리케이션의 버전 제약 조건 등을 지정할 수도 있습니다.
- values.yaml: Helm 차트의 기본 구성 값을 정의합니다. 애플리케이션의 설정 옵션, 환경 변수, 리소스 크기 등을 설정할 수 있습니다. values.yaml 파일에 정의된 값은 템플릿 파일 내에서 사용될 수 있으며, 차트를 배포할 때 사용자 지정 값으로 오버라이드할 수도 있습니다.
Create monitoring namespace
1
2
3
4
apiVersion: v1
kind: Namespace
metadata:
name: monitoring
1
kubectl apply -f monitoring-namespace.yaml
Customizing the Chart values.yaml
- 메트릭 수집 주기와 보존기간, 그리고 메트릭을 저장할 PV의 사이즈와 리소스 제한량은 최대한 적게 사용함으로써 불필요한 비용을 낭비하지 않음
- 사전 준비 단계에서 생성한 StorageClass를 사용
- 각 컴포넌트의 리소스 요쳥량과 제한값을 동일하게 설정해서 QoS를 Guaranteed가 되도록하여 안정성을 높임
- Prometheus가 기본적으로 같은 네임스페이스의 ServiceMonitor로 서비스를 디스커버리 하도록 설정되어 있기 때문에 이것을 Disable하고 다른 네임스페이스의 ServiceMonitor를 탐색할 수 있도록 설정
- 추후 테넌트별 리소스/애플리케이션 메트릭 구분을 위해 라벨링
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
# -------------------Global-------------------
global:
# 프라이빗 레지스트리 사용 시 활용
imageRegistry: ""
imagePullSecrets: []
commonLabels:
cluster: hyper-v-dev
tenant: monitoring
# -------------------Global-Disable-------------------
kubeControllerManager:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
kubeProxy:
enabled: false
# -------------------kubelet-------------------
kubelet:
enabled: true
namespace: kube-system
serviceMonitor:
additionalLabels:
cluster: hyper-v-dev
tenant: monitoring
# -------------------kubeStateMetrics-------------------
kubeStateMetrics:
enabled: true
# Configuration for kube-state-metrics subchart
kube-state-metrics:
prometheus:
monitor:
enabled: true
additionalLabels:
cluster: hyper-v-dev
tenant: monitoring
# -------------------Alertmanager-------------------
alertmanager:
# PDB 설정
podDisruptionBudget:
enabled: false
minAvailable: 1
maxUnavailable: ""
# 서비스 설정
service:
port: 9093
targetPort: 9093
type: NodePort
nodePort: 30903
# 파드 스펙 설정
alertmanagerSpec:
# 파드개수
replicas: 1
resources:
limits:
cpu: 200m
memory: 1Gi
requests:
cpu: 200m
memory: 1Gi
# 스토리지 설정
storage:
volumeClaimTemplate:
spec:
storageClassName: nfs-client
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
# -------------------Grafana-------------------
grafana:
enabled: true
# 대시보드 타임존
defaultDashboardsTimezone: kst
# 어드민 암호
adminPassword: admin
service:
portName: http-web
type: NodePort
port: 3000
targetPort: 3000
nodePort: 30001
persistence:
enabled: true
type: sts
storageClassName: "nfs-client"
accessModes:
- ReadWriteOnce
size: 5Gi
finalizers:
- kubernetes.io/pvc-protection
# -------------------PrometheusOperator-------------------
prometheusOperator:
resources:
limits:
cpu: 200m
memory: 1Gi
requests:
cpu: 200m
memory: 1Gi
# Prometheus Operator와 Kubernetes apiserver 간의 상호작용을 특정 네임스페이스로 제한
# 다른 네임스페이스에 있는 모든 CRDs 관리하려면 {}으로 설정
namespaces: {}
# -------------------Promtetheus-------------------
prometheus:
# 서비스 설정
service:
port: 9090
targetPort: 9090
type: NodePort
nodePort: 30090
# PDB 설정
podDisruptionBudget:
enabled: false
minAvailable: 1
maxUnavailable: ""
# 파드 스펙 설정
prometheusSpec:
# 서비스모니터 설정 -> 다른 네임스페이스에 있는 Service Monitor 사용을 위해 설정
# By default, Prometheus only discovers PodMonitors within its own namespace.
# This should be disabled by setting podMonitorSelectorNilUsesHelmValues to false
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelector:
matchLabels:
tenant: monitoring
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelector:
matchLabels:
tenant: monitoring
# 추가적인 스크래핑 구성
additionalScrapeConfigs: []
# 메트릭 스크랩
scrapeInterval: "30s"
scrapeTimeout: ""
evaluationInterval: ""
# 토폴로지 & 스케쥴링 옵션
tolerations: []
topologySpreadConstraints: []
nodeSelector: {}
podAntiAffinity: ""
podAntiAffinityTopologyKey: kubernetes.io/hostname
affinity: {}
externalLabels:
cluster: hyper-v-dev
tenant: monitoring
# 메트릭 보존 기간
retention: 12h
# 메트릭 최대 사이즈
retentionSize: "5GiB"
# 파드 개수
replicas: 1
resources:
limits:
cpu: 400m
memory: 2Gi
requests:
cpu: 400m
memory: 2Gi
# 스토리지 설정
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: nfs-client
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
Install Helm Chart
1
helm install -f custom-values.yaml kube-prometheus-stack prometheus-community/kube-prometheus-stack -n monitoring
배포 확인
1
2
3
4
helm list -n monitoring
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prometheus-stack monitoring 3 2024-05-03 16:49:24.436905839 +0900 KST deployed kube-prometheus-stack-58.3.3 v0.73.2
1
kubectl get all -n monitoring
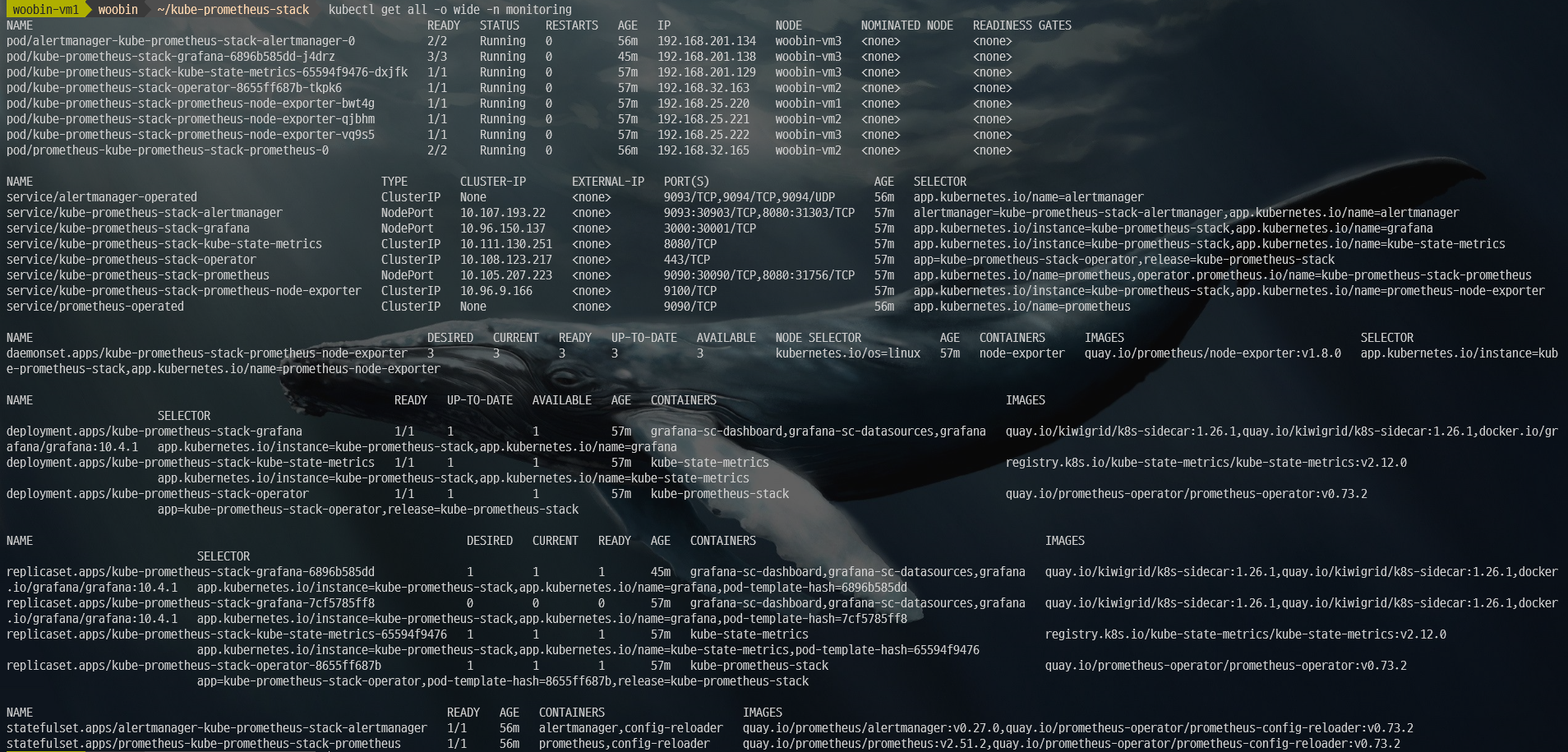
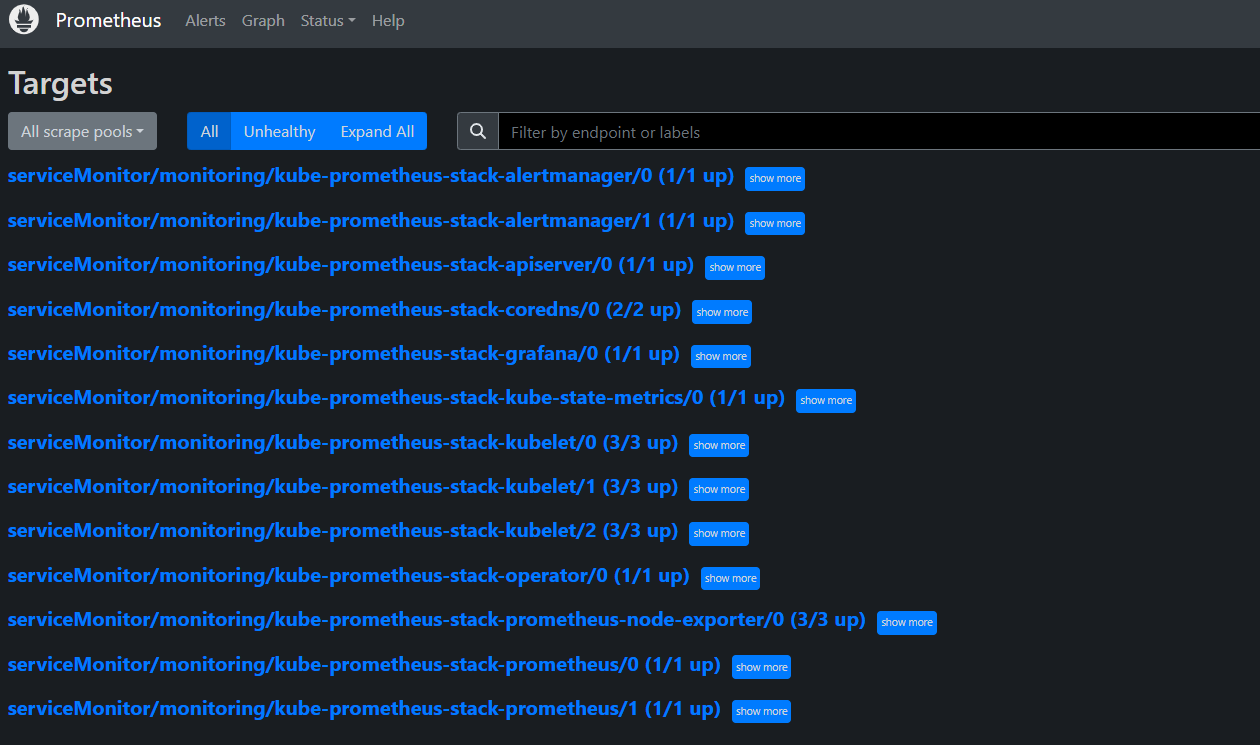
참고) 배포 업데이트/삭제
배포 업데이트
1
helm upgrade -f custom-values.yaml kube-prometheus-stack prometheus-community/kube-prometheus-stack -n monitoring
배포 삭제
1
helm uninstall kube-prometheus-stack -n monitoring1 2 3 4 5 6 7 8 9 10
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com \ alertmanagers.monitoring.coreos.com \ podmonitors.monitoring.coreos.com \ probes.monitoring.coreos.com \ prometheusagents.monitoring.coreos.com \ prometheuses.monitoring.coreos.com \ prometheusrules.monitoring.coreos.com \ scrapeconfigs.monitoring.coreos.com \ servicemonitors.monitoring.coreos.com \ thanosrulers.monitoring.coreos.com
1 2 3 4 5 6 7 8
kubectl delete pv [pv name] --grace-period=0 --force kubectl edit pv (pv name) Find the following in the manifest file finalizers: - kubernetes.io/pv-protection ... and delete it.
1 2 3 4 5 6 7 8
kubectl delete pvc [pvc name] --grace-period=0 --force kubectl edit pvc (pv name) Find the following in the manifest file finalizers: - kubernetes.io/pv-protection ... and delete it.
Grafana
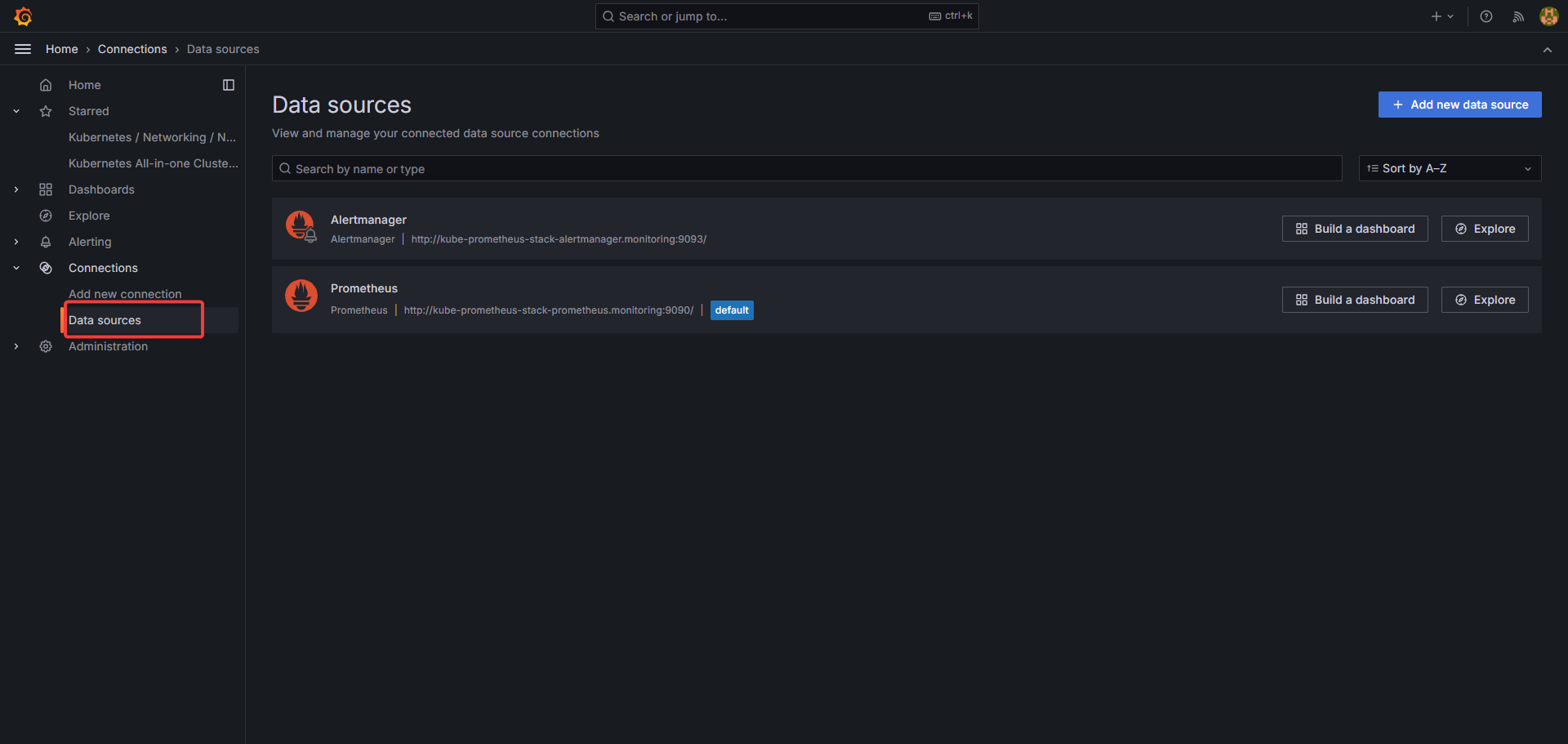
NodePort로 Grafana에 접속하여 연결된 Grafana 데이터소스 확인
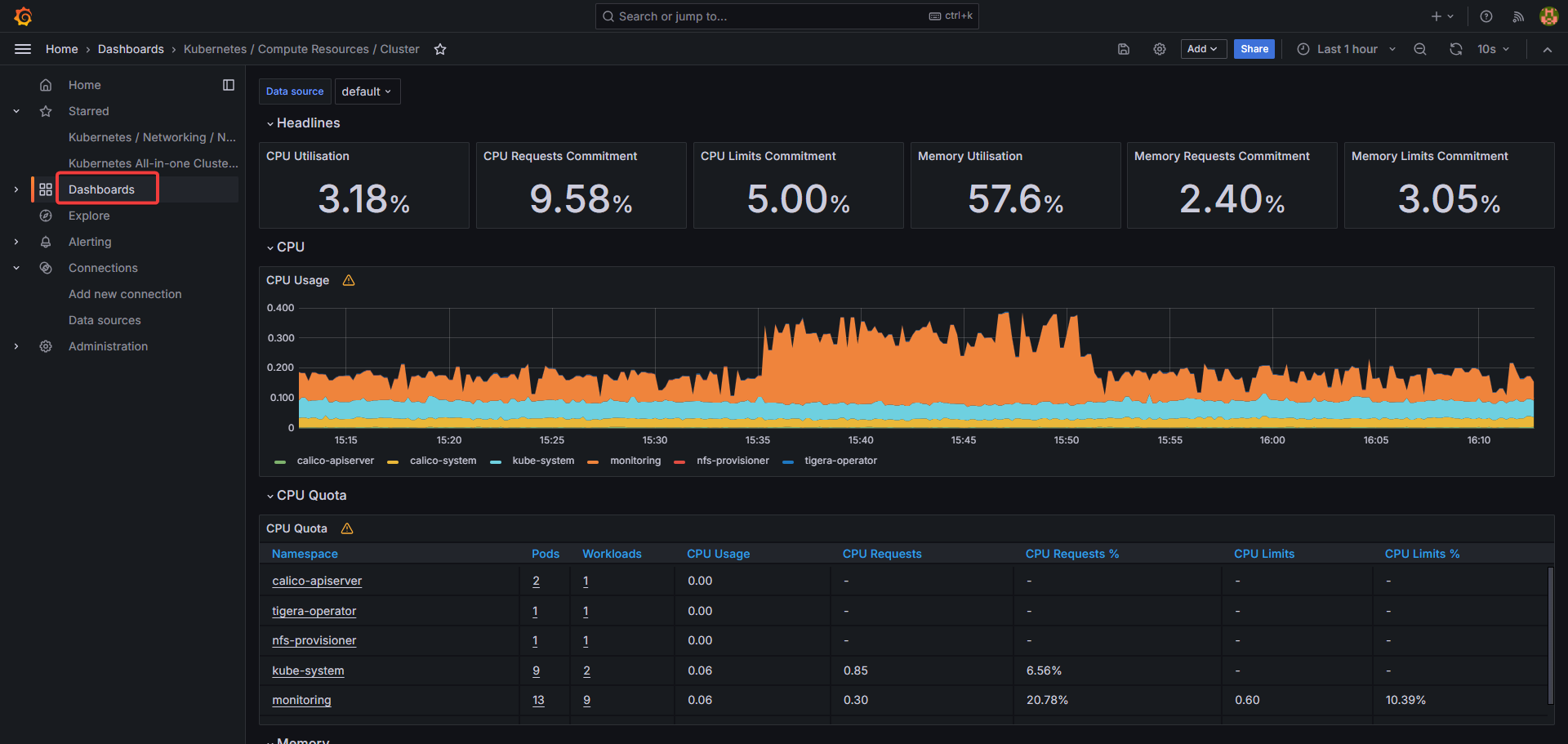
kube-prometheus-stack을 통해 자동 생성된 대시보드 확인