
연구 과제를 진행하기 위해 참고한 강화학습 관련 논문을 요약 정리한 글이다.
본 논문을 선정한 이유
- ACM(Association for Computing Machinery) Recommender Systems conference(RecSys)에 기재된 논문으로 인용지수가 높다.
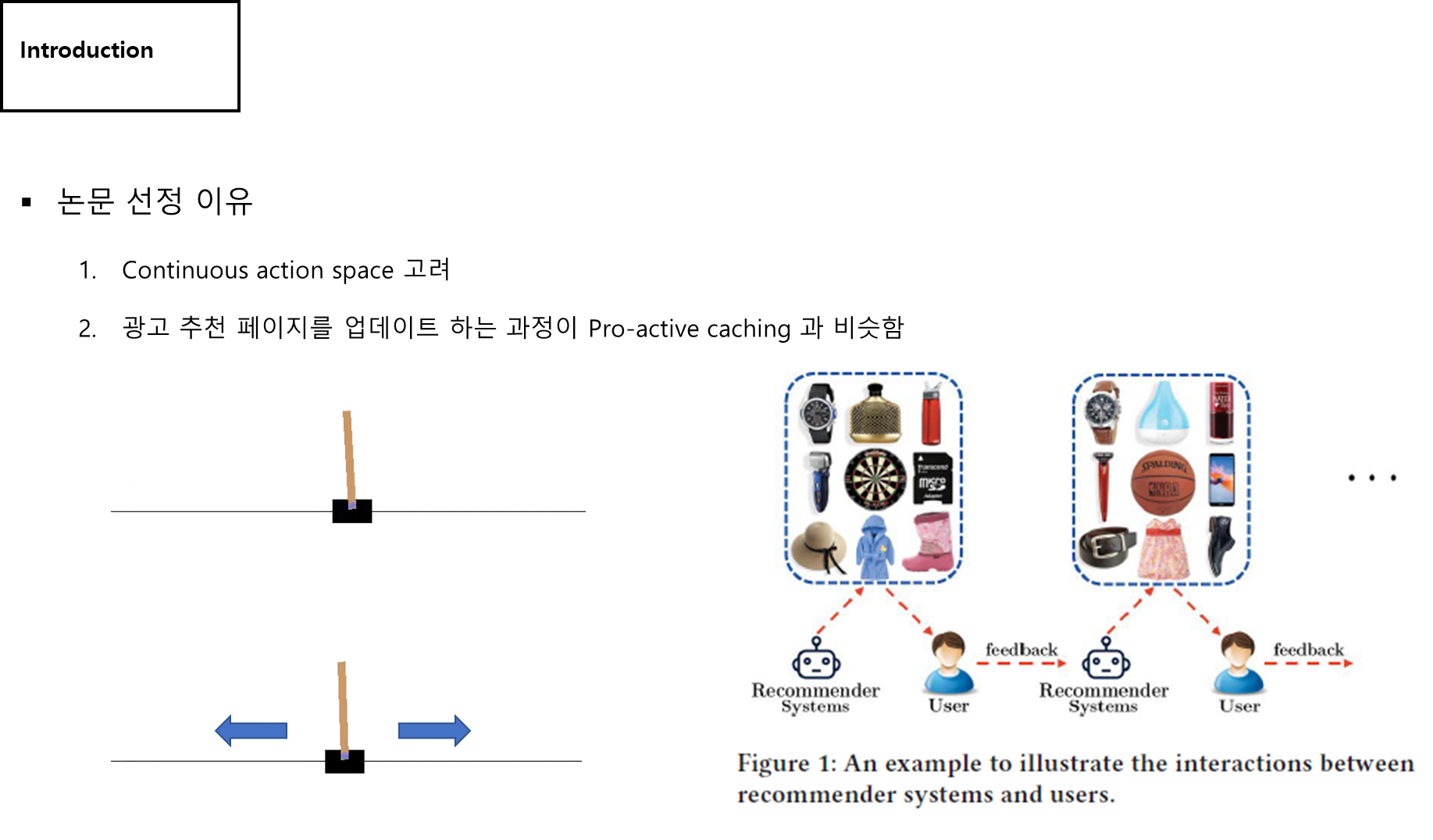
- DDPG 사용하면서 continuous action space를 고려함(연구 과제에서 진행하고자 하는 방향과 유사)




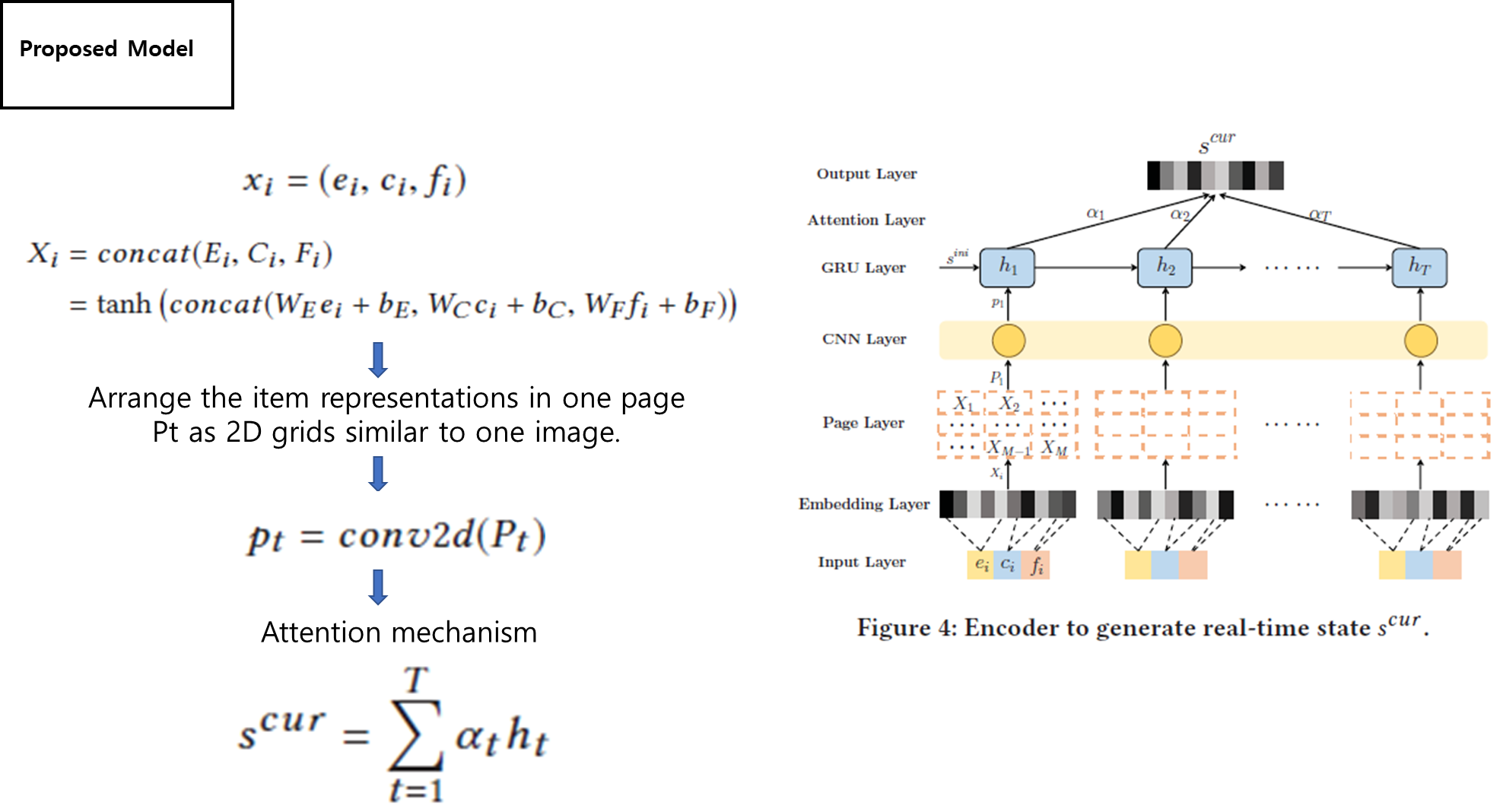
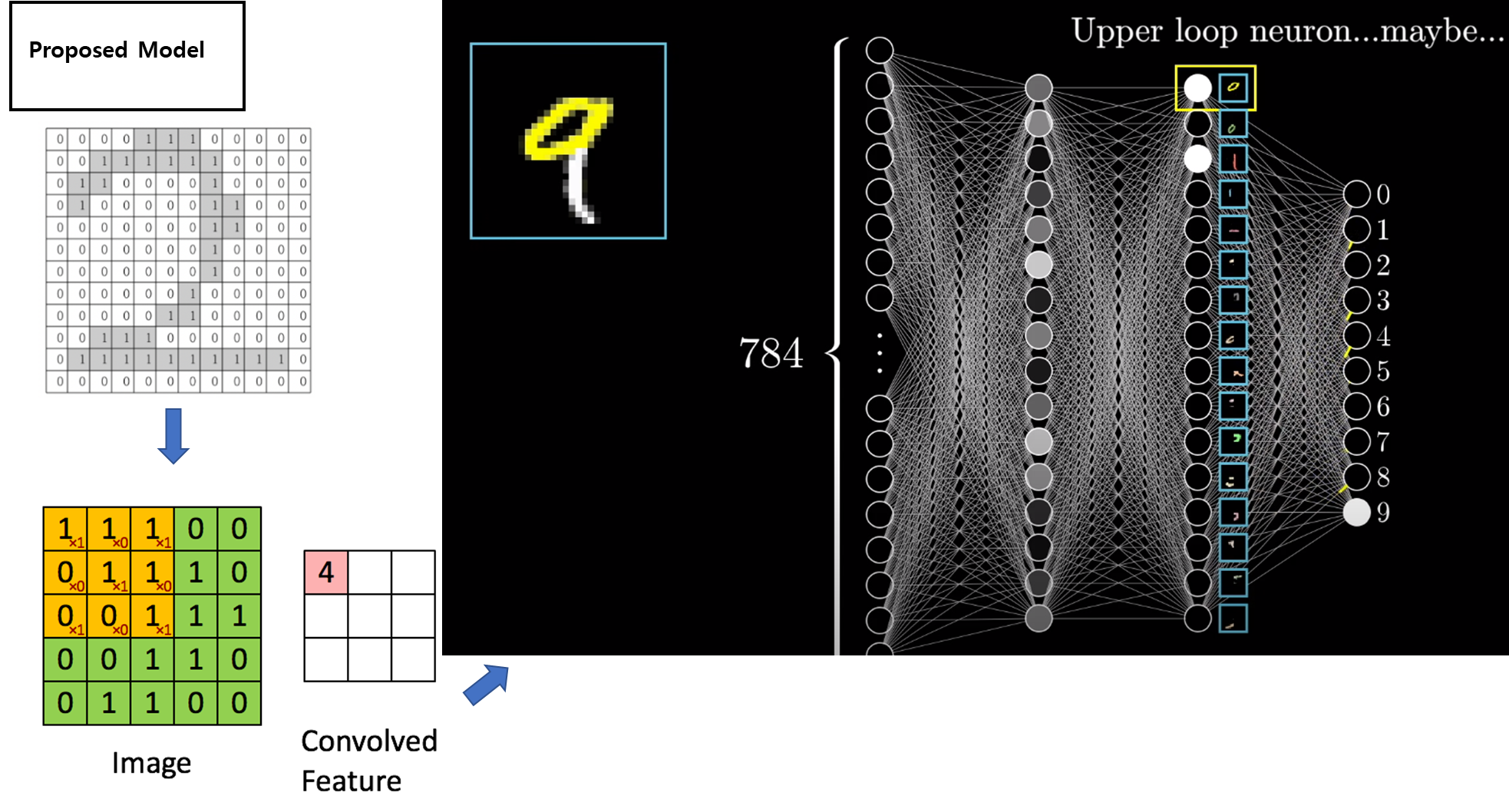

- 우리는 deconvolution을 통해 feature map을 역추적하면 특정 필터가 처음의 인풋이미지에서 담당하는 부분을 시각적으로 알 수 있다는 것
- 딥러닝에서의 deconvolution은 정확한 연산을 한다기보다 그 개념만을 취한다.
- deconvoltuion은 인풋-conv-아웃풋에서 아웃풋을 인풋으로 완전히(혹은 최대한) 되돌리는 것이 아니라 적당히 근사치를 reconstruction(특히 해상도)하는데 목적을 둔다.


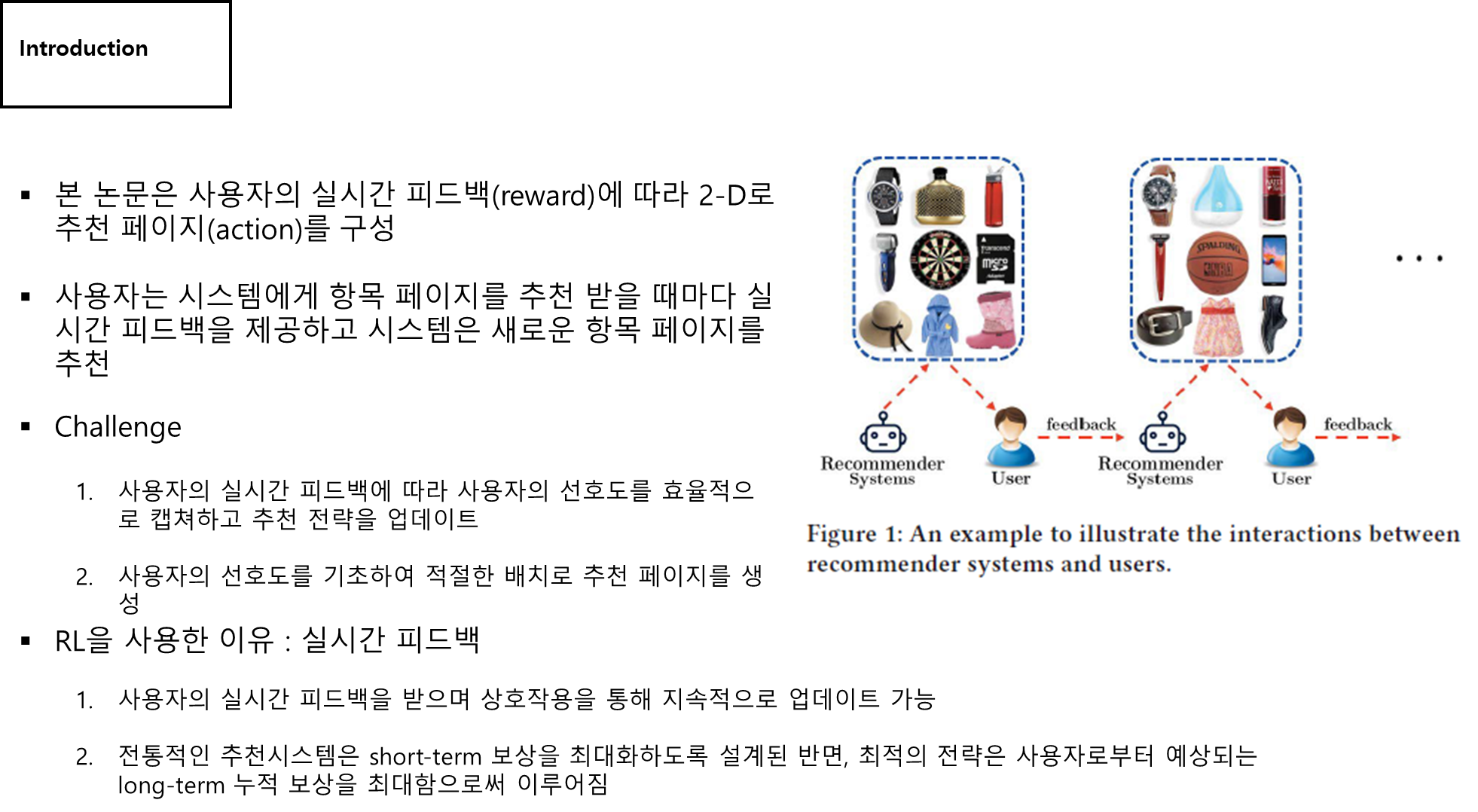
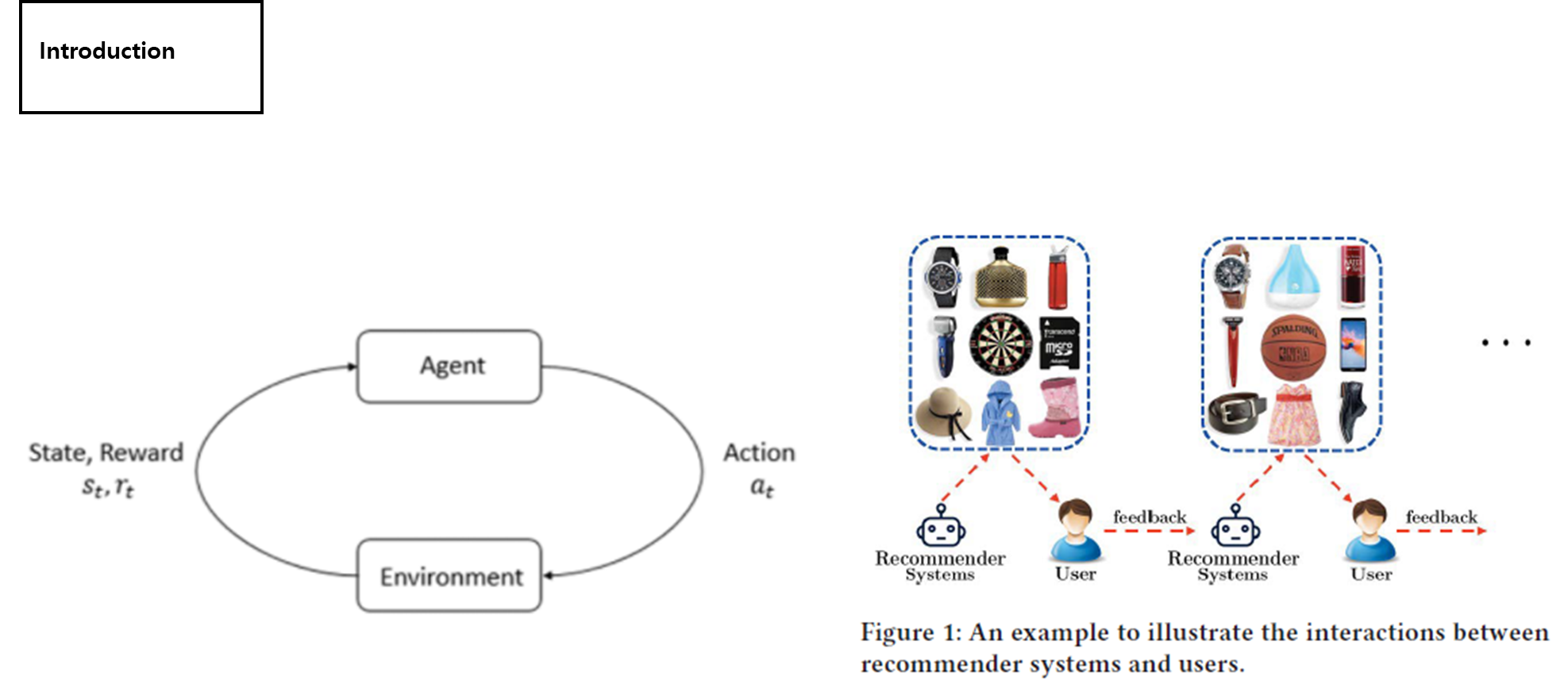
- 페이지 전체를 만든 게 action이기 때문에 그에 대한 즉각적인 보상이 됨
- 우리 프로젝트에서도 즉각적인 보상이 필요함. 사용자의 캐싱 요청 -> 피드백 -> 보상 ?
- 콘텐츠 시청 시간도 보상으로 줄 수 있을까? (장기적인 보상)
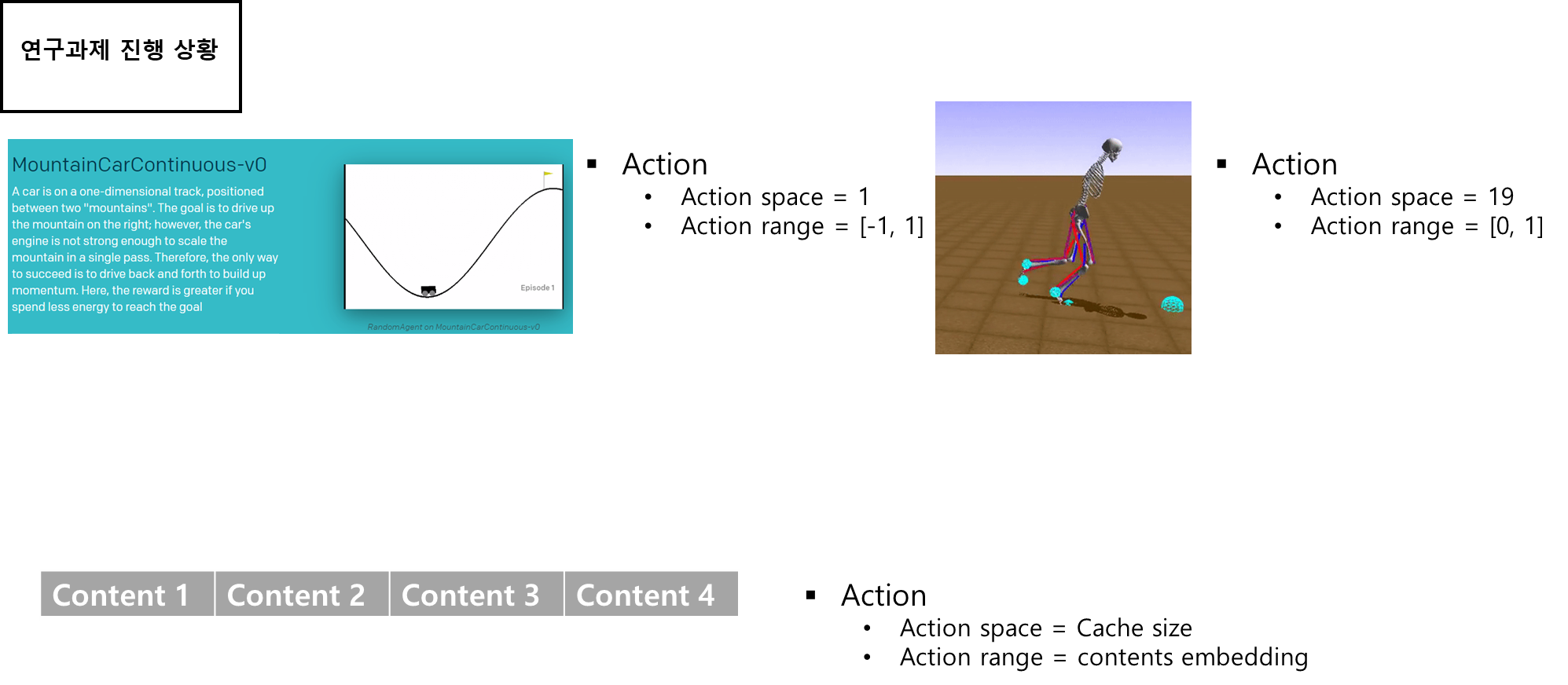
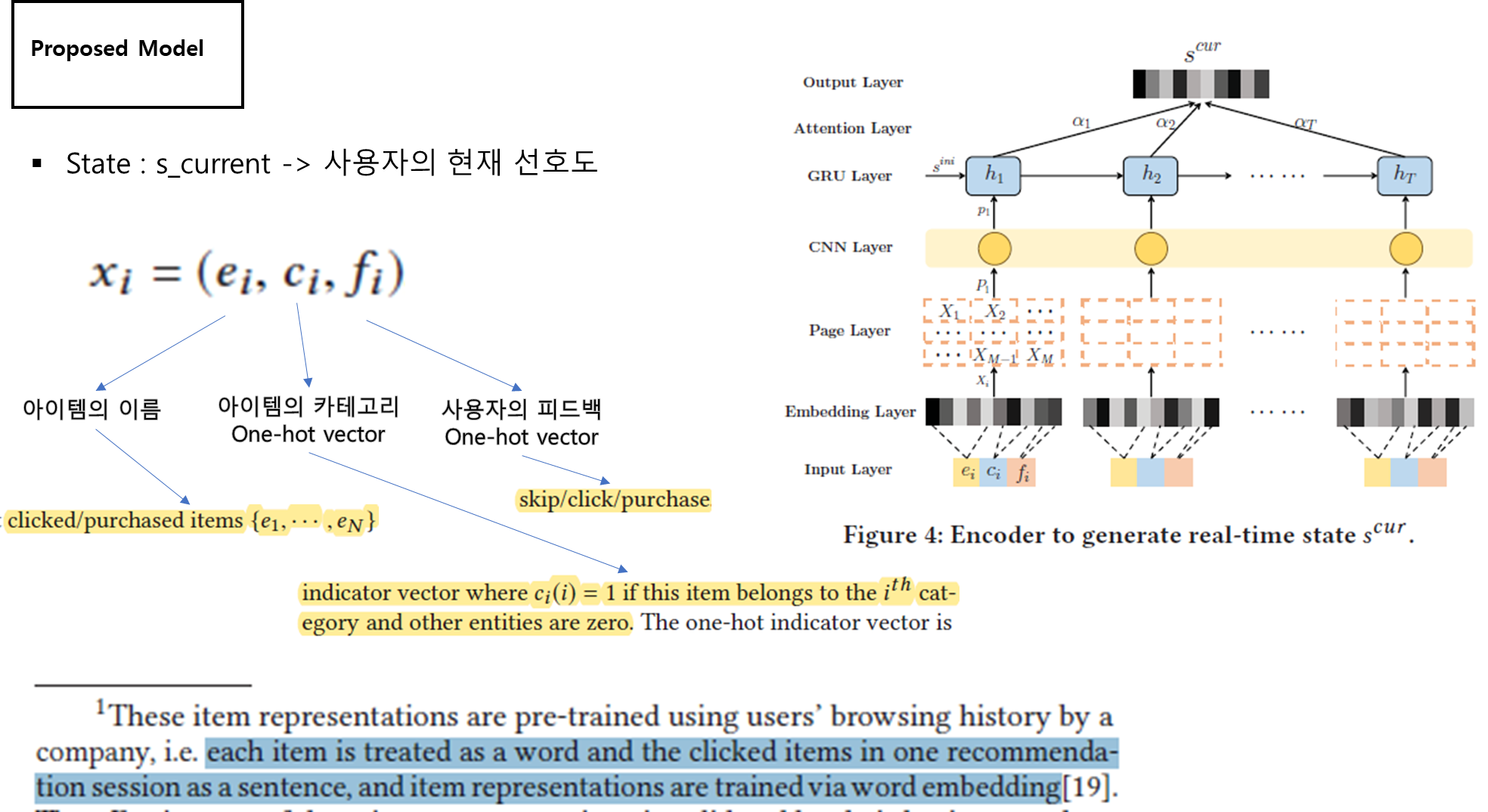
- 콘텐츠를 구분할 수 있게 임베딩 할 수 있다면 본 논문과 비슷하게 캐싱 시스템을 구현할 수 있지 않을까?